Every system you interact with in 2026 — your bank, your streaming service, your search engine, your food delivery app — runs on distributed systems. A distributed system is a collection of computers working together to appear as a single coherent system to users. Designing, building, and reasoning about these systems is one of the highest-leverage skills in backend and infrastructure engineering. This Distributed Systems Tutorial 2026 is your complete path to Learn Distributed Systems from scratch: starting with why distribution matters, working through the CAP Theorem and the fundamental trade-offs, covering Scalability in Distributed Systems and Fault Tolerance, building Microservices Architecture patterns, exploring Distributed Databases, and closing with a Distributed Systems Roadmap and career guide. Whether you are a software engineer preparing for system design interviews or building production systems — this Distributed Computing Guide gives you the depth and the practical code to Learn Distributed Systems with genuine understanding.
Related Article: Top BTech Colleges in India 2026
Table of Contents
- Distributed Systems Fundamentals — Why Distribution and Core Challenges
- CAP Theorem — Consistency, Availability, and Partition Tolerance
- Scalability in Distributed Systems — Horizontal Scaling and Load Balancing
- Fault Tolerance — Replication, Consensus, and Failure Handling
- Microservices Architecture — Service Design and Communication
- Distributed Databases — Sharding, Replication, and Consistency
- Distributed Systems Roadmap — Career Path and System Design Interview Guide
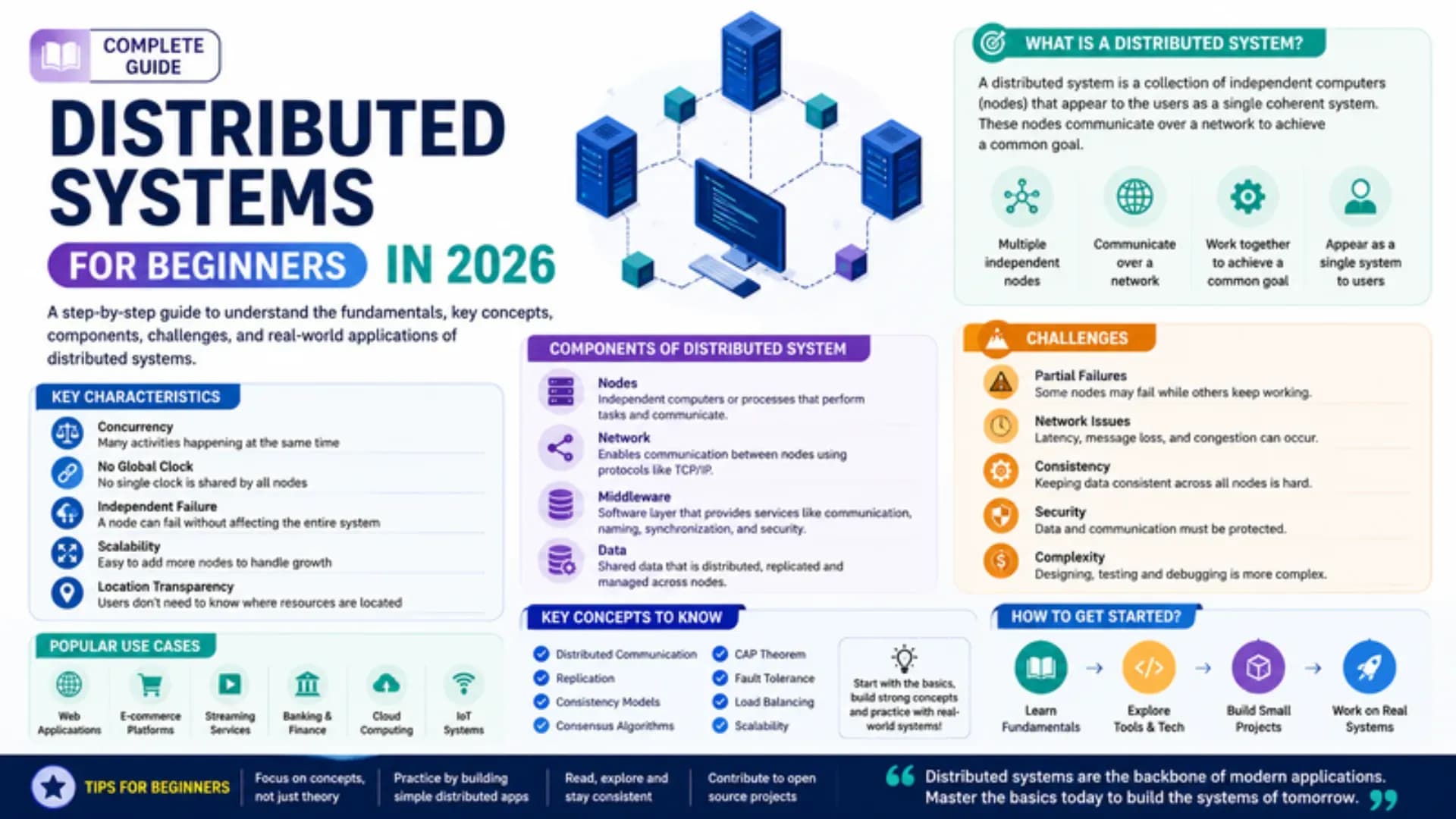
Distributed Systems Fundamentals — Why Distribution and Core Challenges
A single machine has hard limits — CPU, RAM, disk, and network bandwidth are all finite. When the load on a system exceeds what one machine can handle, or when continuous availability is required even when machines fail, distribution is the answer. Distributed Systems for Beginners must first understand that distribution solves real problems but introduces an entirely new class of challenges that do not exist on a single machine.
# The eight fallacies of distributed computing (Peter Deutsch, Sun Microsystems, 1994)
# Every engineer who designs distributed systems violates these at least once.
#
# 1. The network is reliable
# Reality: packets are dropped, connections are reset, routers fail
# Design response: retries with exponential backoff, idempotency, timeouts
#
# 2. Latency is zero
# Reality: a cross-datacenter call adds 50-150ms; in-datacenter 0.5-5ms
# Design response: batch requests, async communication, colocate hot data
#
# 3. Bandwidth is infinite
# Reality: bandwidth has cost and limits; WAN bandwidth is expensive
# Design response: compression, pagination, delta sync, CDN for static data
#
# 4. The network is secure
# Reality: traffic can be intercepted, replayed, spoofed
# Design response: TLS everywhere, mTLS for service-to-service, zero trust
#
# 5. Topology doesn't change
# Reality: IPs change, services scale up/down, nodes join and leave
# Design response: service discovery, health checks, dynamic load balancing
#
# 6. There is one administrator
# Reality: multiple teams, multiple services, multiple failure domains
# Design response: contract testing, versioned APIs, chaos engineering
#
# 7. Transport cost is zero
# Reality: serialisation + network overhead is real; JSON is expensive at scale
# Design response: Protocol Buffers, MessagePack, binary serialisation
#
# 8. The network is homogeneous
# Reality: different OS, hardware, network equipment, language runtimes
# Design response: language-agnostic protocols (HTTP, gRPC), stable contracts
# Key distributed systems vocabulary:
distributed_terms = {
"Node": "Any machine in the distributed system (server, container, VM)",
"Partition": "Network split: some nodes cannot communicate with others",
"Latency": "Time to complete a single operation end-to-end",
"Throughput": "Operations per second the system can sustain",
"Replication": "Keeping copies of data on multiple nodes for durability",
"Consensus": "Agreement among nodes on a single value despite failures",
"Idempotency": "Operation produces same result when applied multiple times",
"Eventual Consistency": "All replicas converge to same value if updates stop",
"Strong Consistency": "Every read sees the most recent write, always",
}import time, random
# Demonstrating the retry with exponential backoff pattern — essential in distributed work:
def call_remote_service(payload: dict) -> dict:
"""Simulates an unreliable remote call that fails 60% of the time."""
if random.random() < 0.6:
raise ConnectionError("Service temporarily unavailable")
return {"status": "ok", "data": payload}
def retry_with_backoff(func, *args, max_retries=5, base_delay=0.1, jitter=True):
"""
Exponential backoff with jitter — the correct way to retry in distributed systems.
Jitter is critical: without it, all retrying clients hit the server simultaneously.
"""
for attempt in range(max_retries):
try:
result = func(*args)
print(f" Success on attempt {attempt + 1}")
return result
except ConnectionError as e:
if attempt == max_retries - 1:
raise # final attempt failed — propagate
delay = base_delay * (2 ** attempt) # 0.1, 0.2, 0.4, 0.8, 1.6s
if jitter:
delay *= random.uniform(0.5, 1.5) # ±50% randomisation
print(f" Attempt {attempt + 1} failed: {e}. Retrying in {delay:.2f}s")
time.sleep(delay)
random.seed(42)
try:
result = retry_with_backoff(call_remote_service, {"user_id": 123})
print(f"Final result: {result}")
except ConnectionError:
print("Service unavailable after all retries — circuit breaker should trigger")CAP Theorem — Consistency, Availability, and Partition Tolerance
The CAP Theorem (Eric Brewer, 2000) is the most important theoretical framework in Distributed Systems Architecture. It states that a distributed system can guarantee at most two of three properties simultaneously — Consistency, Availability, and Partition Tolerance. Understanding the trade-off is essential for every design decision involving distributed storage.
# CAP Theorem — the definitive explanation:
#
# CONSISTENCY (C):
# Every read receives the most recent write or an error.
# All nodes see the same data at the same time.
# Example: bank balance — you must never see stale data when withdrawing
#
# AVAILABILITY (A):
# Every request receives a (non-error) response — without guarantee it's latest.
# The system stays operational even when some nodes are down.
# Example: product page still loads even if inventory DB is partitioned
#
# PARTITION TOLERANCE (P):
# The system continues operating despite network partitions.
# In practice: P is not optional in any real distributed system.
# Networks DO partition — the real choice is between C and A when they do.
#
# The actual trade-off in 2026: C vs A during a partition.
# CP systems: Return error/timeout rather than return stale data (banks, Zookeeper, HBase)
# AP systems: Return possibly stale data rather than return error (Cassandra, DynamoDB, CouchDB)
# CA is impossible in a distributed system (you can't avoid partitions)
cap_examples = {
"CP (Consistent + Partition Tolerant)": {
"Examples": "Apache Zookeeper, HBase, MongoDB (default), Redis Cluster",
"Behaviour": "During partition: refuse writes/reads on minority partition → data safe",
"Use when": "Financial transactions, seat reservations, distributed locks",
},
"AP (Available + Partition Tolerant)": {
"Examples": "Apache Cassandra, DynamoDB, CouchDB, Riak",
"Behaviour": "During partition: serve stale reads, accept writes → eventual consistency",
"Use when": "Social media feeds, shopping carts, DNS, CDN content",
},
}
for model, details in cap_examples.items():
print(f"\n{model}")
for k, v in details.items():
print(f" {k:12}: {v}")# PACELC — the more nuanced successor to CAP (Daniel Abadi, 2012):
#
# CAP only describes behaviour during partitions.
# PACELC asks: what about when there IS no partition (normal operation)?
#
# "If Partition → Availability vs Consistency
# Else (no partition) → Latency vs Consistency"
#
# Why this matters: even without failures, strong consistency requires
# coordination (consensus rounds) which ADDS latency.
# Eventual consistency allows lower latency but weaker guarantees.
#
# PACELC classifications:
pacelc = {
"DynamoDB": "PA/EL — available during partition; low latency (eventual) normally",
"Cassandra": "PA/EL — highly available; trades consistency for latency",
"Zookeeper": "PC/EC — consistent during partition; higher latency (Paxos/ZAB)",
"Spanner": "PC/EC — Google's globally consistent DB; uses TrueTime for sync",
"MongoDB": "PA/EC — available during partition; consistent in normal operation",
}
for db, classification in pacelc.items():
print(f" {db:12} → {classification}")Scalability in Distributed Systems — Horizontal Scaling and Load Balancing
Scalability in Distributed Systems is the ability to handle growing load by adding resources. The two fundamental approaches — vertical scaling (bigger machine) and horizontal scaling (more machines) — have profoundly different implications for system design.
# Vertical vs Horizontal Scaling:
#
# VERTICAL SCALING (scale up): bigger machine
# Pros: simple, no code changes, no distributed complexity
# Cons: physical limits (can't buy infinite RAM), single point of failure,
# expensive at high end, downtime for upgrade
# Ceiling: ~128 cores, ~24TB RAM on largest cloud instances (2026)
#
# HORIZONTAL SCALING (scale out): more machines
# Pros: theoretically unlimited, commodity hardware, fault tolerant
# Cons: distributed complexity, data partitioning challenges, coordination overhead
# Example: Amazon runs hundreds of thousands of commodity servers
# Load Balancing — distributing requests across nodes:
import random
from collections import Counter
class LoadBalancer:
def __init__(self, servers: list[str]):
self.servers = servers
self.current = 0 # for round-robin
self.connections = Counter() # for least-connections
def round_robin(self) -> str:
"""Equal distribution — works when requests are similar cost."""
server = self.servers[self.current % len(self.servers)]
self.current += 1
return server
def least_connections(self) -> str:
"""Route to server with fewest active connections — better for variable-cost requests."""
return min(self.servers, key=lambda s: self.connections[s])
def consistent_hash(self, key: str) -> str:
"""Same key always goes to same server — essential for session affinity and caching."""
index = hash(key) % len(self.servers)
return self.servers[index]
lb = LoadBalancer(["server-1", "server-2", "server-3"])
print("Round-robin: ", [lb.round_robin() for _ in range(6)])
print("Consistent hash for user-42: ", lb.consistent_hash("user-42"))
print("Consistent hash for user-42: ", lb.consistent_hash("user-42")) # same server# Consistent Hashing — the distributed systems way to shard without rehashing everything:
#
# Problem with simple modulo hashing:
# 3 servers → key % 3. Add a 4th server: key % 4
# Almost EVERY key maps to a different server → massive cache misses / data movement
#
# Consistent hashing solution:
# Map servers AND keys onto a ring (hash space: 0 to 2^32)
# Key → walk clockwise until you find a server node
# Adding a server: only keys between new server and its predecessor move
# Removing a server: only keys on that server move to the next clockwise server
# With N servers and K keys: only K/N keys need to move when adding/removing one server
#
# Used by: Amazon DynamoDB, Apache Cassandra, Memcached (ketama), Nginx consistent hashing
import hashlib, bisect
class ConsistentHashRing:
def __init__(self, virtual_nodes=150):
self.ring = {}
self.sorted_keys = []
self.vnodes = virtual_nodes # more vnodes → more even distribution
def _hash(self, key: str) -> int:
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def add_server(self, server: str):
for i in range(self.vnodes):
vkey = self._hash(f"{server}:{i}")
self.ring[vkey] = server
bisect.insort(self.sorted_keys, vkey)
def get_server(self, key: str) -> str:
if not self.ring: raise Exception("No servers in ring")
h = self._hash(key)
idx = bisect.bisect(self.sorted_keys, h) % len(self.sorted_keys)
return self.ring[self.sorted_keys[idx]]
ring = ConsistentHashRing()
for s in ["server-A", "server-B", "server-C"]:
ring.add_server(s)
test_keys = ["user:1001", "user:1002", "order:42", "session:xyz"]
distribution = Counter(ring.get_server(k) for k in test_keys)
for key in test_keys:
print(f" {key:20} → {ring.get_server(key)}")Fault Tolerance — Replication, Consensus, and Failure Handling
Fault Tolerance in distributed systems means the system continues operating correctly even when some components fail. In practice: machines crash, networks partition, disks fail, software has bugs. A fault-tolerant system anticipates these failures and handles them gracefully.
# Replication — keeping data on multiple nodes:
#
# LEADER-FOLLOWER (Primary-Replica):
# All writes go to leader → leader replicates to followers → reads can go to followers
# Pros: simple, consistent reads from leader
# Cons: leader is bottleneck for writes; failover required when leader dies
# Used by: MySQL replication, Redis primary-replica, PostgreSQL streaming replication
#
# MULTI-LEADER:
# Multiple nodes accept writes → replicate to each other
# Pros: write across multiple DCs, no single write bottleneck
# Cons: write conflicts must be resolved (last-write-wins? merge? user?)
# Used by: CouchDB, Google Docs (operational transforms)
#
# LEADERLESS (Dynamo-style):
# Any node accepts writes → propagates to W replicas; reads from R replicas
# Quorum: W + R > N guarantees at least one overlap (N = total replicas)
# Example: N=3, W=2, R=2 → at least one read sees the latest write
# Used by: Amazon DynamoDB, Apache Cassandra, Riak
# Quorum calculation:
def check_quorum(N: int, W: int, R: int) -> dict:
return {
"strong_consistency": W + R > N,
"write_fault_tolerance": N - W, # can lose this many nodes and still write
"read_fault_tolerance": N - R, # can lose this many nodes and still read
}
configs = [(3, 2, 2), (5, 3, 3), (3, 1, 3), (3, 3, 1)]
for N, W, R in configs:
result = check_quorum(N, W, R)
print(f" N={N} W={W} R={R}: {result}")# Circuit Breaker Pattern — preventing cascade failures:
#
# Problem: if Service B is slow, Service A keeps calling it
# → A's threads block → A runs out of thread pool → A fails too
# → Services C, D that call A also fail → cascade failure
#
# Solution: Circuit Breaker (like an electrical circuit breaker)
# States: CLOSED (normal) → OPEN (failing, fail fast) → HALF_OPEN (testing recovery)
from enum import Enum
import time
class State(Enum):
CLOSED = "CLOSED"
OPEN = "OPEN"
HALF_OPEN = "HALF_OPEN"
class CircuitBreaker:
def __init__(self, failure_threshold=5, recovery_timeout=30):
self.state = State.CLOSED
self.failure_count = 0
self.threshold = failure_threshold
self.timeout = recovery_timeout
self.last_failure_time = None
def call(self, func, *args):
if self.state == State.OPEN:
if time.time() - self.last_failure_time > self.timeout:
self.state = State.HALF_OPEN # try recovery
else:
raise Exception("Circuit OPEN — failing fast; not calling downstream")
try:
result = func(*args)
if self.state == State.HALF_OPEN:
self.state = State.CLOSED # recovery successful
self.failure_count = 0
return result
except Exception:
self.failure_count += 1
self.last_failure_time = time.time()
if self.failure_count >= self.threshold:
self.state = State.OPEN # too many failures — open circuit
print(f"Circuit OPENED after {self.failure_count} failures")
raise
# Used by: Netflix Hystrix, Resilience4j, Polly (.NET), Istio (service mesh)Also Read: Top MTech Colleges in India 2026
Microservices Architecture — Service Design and Communication
Microservices Architecture is the dominant pattern for building large-scale distributed applications in 2026. Instead of one large monolithic application, a system is built as a collection of small, independently deployable services — each owning its own data and communicating over well-defined APIs.
# Microservices vs Monolith — when to choose which:
#
# MONOLITH: single deployable unit; all components share one process and database
# Start here: simple to develop, test, debug, and deploy
# Problems at scale: deployment coupling, technology lock-in, scaling bottlenecks
# Rule: don't start with microservices — start monolith and extract as needed
#
# MICROSERVICES: each service independently developed, deployed, and scaled
# Benefits: independent deployment, polyglot tech, team autonomy
# Problems: distributed system complexity (all of this article applies)
# When to move: when Conway's Law friction appears (org structure fighting architecture)
# Microservice design principles:
principles = {
"Single Responsibility": "Each service does ONE thing well — User Service, Payment Service",
"Own Your Data": "Services do NOT share databases; each owns its storage",
"API Contracts": "Services communicate via versioned APIs (REST/gRPC/events)",
"Design for Failure": "Any downstream service can fail; handle it gracefully",
"Decentralised Data": "Different services can use different databases (polyglot persistence)",
"Infrastructure as Code":"Each service owns its deployment config (Docker, Helm)",
}
# Service communication patterns:
#
# SYNCHRONOUS: Request-Response (REST, gRPC)
# Client waits for response — simple, easy to reason about
# Problem: caller blocks; if downstream is slow, caller is slow
# Use for: user-facing operations that need immediate response
#
# ASYNCHRONOUS: Event-driven (Kafka, RabbitMQ, SQS)
# Publisher emits event; consumer processes when ready — decoupled
# Problem: harder to debug; eventual consistency; ordering challenges
# Use for: audit logs, notifications, analytics pipelines, data replication# The Saga Pattern — distributed transactions without 2PC:
#
# Problem: microservices don't share a database.
# You can't use ACID transactions across service boundaries.
# Example: "Place order" needs to: charge payment, reserve inventory, create shipment
# If payment succeeds but inventory reservation fails — how do you rollback payment?
#
# SAGA: sequence of local transactions, each with a compensating transaction to undo
# Two types: Choreography (event-driven) and Orchestration (central coordinator)
# Choreography-based Saga (events):
saga_choreography = {
"Step 1": {
"action": "Order Service creates order",
"event": "OrderCreated published",
"compensate": "Mark order as cancelled",
},
"Step 2": {
"action": "Payment Service consumes OrderCreated → charges card",
"event": "PaymentProcessed OR PaymentFailed",
"compensate": "Issue refund (on PaymentFailed)",
},
"Step 3": {
"action": "Inventory Service consumes PaymentProcessed → reserves stock",
"event": "StockReserved OR StockInsufficient",
"compensate": "Publish StockInsufficient → Payment Service refunds",
},
"Step 4": {
"action": "Shipping Service creates shipment",
"event": "ShipmentCreated OR ShipmentFailed",
"compensate": "Release inventory + refund payment",
},
}
# Key insight: each compensating transaction must be idempotent
# (safe to execute multiple times in case of retry)Distributed Databases — Sharding, Replication, and Consistency Models
Distributed Databases are the most complex component of any distributed system — they must manage data durability, consistency, and availability simultaneously across multiple machines that can fail at any time.
# Database Sharding — horizontal partitioning of data across nodes:
#
# Why shard: single DB can't handle the write load or the data volume
#
# RANGE SHARDING: partition by value range
# Shard 1: user_id 1–1,000,000
# Shard 2: user_id 1,000,001–2,000,000
# Pros: range queries efficient (find users 100–200 hits one shard)
# Cons: hotspots if new users always hit the latest shard (uneven load)
#
# HASH SHARDING: shard = hash(key) % num_shards
# Pros: even distribution by default
# Cons: range queries hit ALL shards (scatter-gather); resharding is expensive
#
# DIRECTORY-BASED: lookup table maps key → shard
# Pros: most flexible; can rebalance by updating table
# Cons: lookup service is a single point of failure; extra round trip
def determine_shard(user_id: int, num_shards: int = 4) -> str:
shard = user_id % num_shards
return f"shard-{shard}"
# Demonstrate hash distribution across shards:
user_ids = list(range(1, 21))
shard_distribution = Counter(determine_shard(uid) for uid in user_ids)
print("Shard distribution:", dict(sorted(shard_distribution.items())))
# Should show roughly equal distribution: {shard-0: 5, shard-1: 5, shard-2: 5, shard-3: 5}
# The cross-shard join problem:
# SELECT * FROM orders JOIN users ON orders.user_id = users.id WHERE user_id = 42
# → user 42 is on shard-2; but orders for user 42 are also on shard-2 (if sharded by user_id)
# → co-locate related data on the same shard by using the same shard key
# → this is why DynamoDB's partition key design is so critical# Distributed database comparison — choosing the right one:
#
# POSTGRESQL (single node → read replicas → Citus/Postgres for horizontal sharding)
# Strong ACID, rich SQL, best for complex queries and joins
# Scale: vertical primary + read replicas handles most apps
# Limit: write scaling requires sharding (Citus) or sharding in application layer
#
# APACHE CASSANDRA
# Leaderless, AP, eventual consistency, tunable consistency (ANY to ALL)
# Strengths: write-heavy workloads, time-series, wide-column access patterns
# Weakness: no joins, no aggregations, data model must match queries
# Used by: Netflix, Apple, Discord (100B messages), Uber
#
# APACHE KAFKA (not a DB — a distributed log / event streaming platform)
# Ordered, replicated log of events; consumers read at their own pace
# Strengths: decoupled producers/consumers, replay events, 1M msgs/sec throughput
# Used for: event sourcing, microservices integration, real-time analytics pipelines
# Used by: LinkedIn (originator), Airbnb, Uber, PayU, Zepto
#
# GOOGLE SPANNER / AWS AURORA (NewSQL)
# Globally distributed + ACID + SQL — the best of both worlds, high cost
# Spanner uses TrueTime (GPS + atomic clocks) for global consistency
# Used by: Google (internal), large fintech on GCP, PlanetScale (MySQL-compatible)
db_selection_guide = {
"OLTP + strong consistency": "PostgreSQL → CockroachDB/Spanner for global scale",
"High write throughput": "Apache Cassandra or DynamoDB",
"Caching layer": "Redis (in-memory, sub-millisecond latency)",
"Full-text search": "Elasticsearch or OpenSearch",
"Event streaming": "Apache Kafka or Amazon Kinesis",
"Graph data": "Neo4j or Amazon Neptune",
"Time-series (IoT/metrics)": "InfluxDB, TimescaleDB, or Prometheus",
}Distributed Systems Roadmap — Career Path and System Design Interview Guide
# Distributed Systems Roadmap — 12-month structured learning path:
#
# MONTHS 1–2 — Foundations:
# ✓ Book: "Designing Data-Intensive Applications" (Martin Kleppmann) — the definitive text
# ✓ Understand: TCP/IP, DNS, HTTP/2, TLS — the network layer first
# ✓ Understand: relational database internals — B-trees, ACID, WAL, indexes
# ✓ Build: a key-value store from scratch in Python or Go (teaches storage engine basics)
#
# MONTHS 3–4 — Core Distributed Concepts:
# → CAP theorem, PACELC, consistency models (this article — go deeper)
# → Raft consensus algorithm (https://raft.github.io — visualisation + paper)
# → Paper: "Dynamo: Amazon's Highly Available Key-Value Store" (2007)
# → Paper: "Bigtable: A Distributed Storage System for Structured Data" (Google 2006)
# → Build: replicated log with leader election in Python (Raft simplified)
#
# MONTHS 5–6 — Practical Systems:
# → Set up Apache Kafka locally; build a producer-consumer pipeline
# → Run Apache Cassandra; understand partition keys and clustering columns
# → Deploy a 3-service microservices system with Docker Compose
# → Implement circuit breaker, retry with backoff, health checks
#
# MONTHS 7–8 — Observability and Operations:
# → Metrics: Prometheus + Grafana (install locally; instrument a service)
# → Distributed tracing: Jaeger or Zipkin; understand trace IDs and spans
# → Logging: structured JSON logs; correlation IDs across services
# → Chaos engineering: kill a node deliberately; observe system behaviour
#
# MONTHS 9–10 — Kubernetes and Cloud Infrastructure:
# → Kubernetes fundamentals (Pods, Services, Deployments, ConfigMaps)
# → Service mesh: Istio or Linkerd (mTLS, traffic management, observability)
# → Cloud: AWS/GCP/Azure — VPC, load balancers, managed services
# → Infrastructure as Code: Terraform for provisioning
#
# MONTHS 11–12 — System Design Mastery + Job Search:
# → Practice: design URL shortener, rate limiter, chat system, ride-sharing backend
# → Book: "System Design Interview" volumes 1 and 2 (Alex Xu)
# → Contribute to open-source distributed systems (etcd, Kafka, Cassandra)
# → Target companies: Google, Amazon, Flipkart, Meesho, Razorpay, Juspay, Zepto# System Design Interview — how to structure a distributed systems design:
#
# Example: "Design a URL Shortener (like bit.ly)"
#
# STEP 1 — Clarify requirements and scale:
requirements = {
"functional": ["Shorten URL → short code", "Redirect short code → original URL"],
"non_functional": [
"100M URLs created per day (1,160 writes/sec)",
"10B redirects per day (115,000 reads/sec) — read-heavy 100:1",
"URL stored for 5 years",
"P99 redirect latency < 10ms",
],
}
# STEP 2 — Capacity estimation:
writes_per_sec = 100_000_000 / (24 * 3600) # ~1,160 /sec
reads_per_sec = 10_000_000_000 / (24 * 3600) # ~115,740 /sec
bytes_per_url = 500 # bytes
storage_5yr = 100_000_000 * 365 * 5 * bytes_per_url # ~91 TB
# STEP 3 — High-level design:
design_components = {
"API Gateway": "Rate limiting, auth, routing → write or read service",
"Write Service": "Generate 7-char base62 code (62^7 = 3.5T URLs), store to DB",
"Read Service": "Lookup code → return redirect; check cache first",
"Cache (Redis)": "Cache hot URLs (80/20: 20% of URLs = 80% of traffic)",
"Database": "Key-value: code → URL; Cassandra (write-heavy, auto-shards)",
"CDN": "Geographic distribution for read latency < 10ms globally",
}
# STEP 4 — Deep dive (CAP choice, sharding strategy, failure handling):
# URL shortener: AP > CP (stale redirect for 1s is fine; unavailability is not)
# Shard by: first 2 chars of short code → distributes writes evenly
# Failure handling: multi-region Cassandra, Redis cluster with read replicasThe single most important book in this field: Martin Kleppmann's "Designing Data-Intensive Applications" (DDIA). Every distributed systems engineer in 2026 who is working at or interviewing for senior roles has read it. If you have not read it, stop everything and read it. It is the most complete, practically grounded, and intellectually honest book written about distributed systems. The code in this tutorial is a complement to DDIA's depth — not a substitute for it.
CHECK OUT: Top Colleges in Ranchi 2026
Explore More
Conclusion
This Distributed Systems Tutorial 2026 has covered the complete foundation: the eight fallacies and why distribution is hard, the CAP Theorem and PACELC with real system classifications, Scalability in Distributed Systems through consistent hashing and load balancing, Fault Tolerance with replication, quorum, and the circuit breaker pattern, Microservices Architecture with the Saga pattern for distributed transactions, Distributed Databases with sharding strategies and database selection guidance, and the complete Distributed Systems Roadmap with system design interview technique.
Learn Distributed Systems is a multi-year journey — this Distributed Computing Guide gives you the conceptual framework and practical patterns, but depth comes from building real systems, reading the original papers, and debugging production failures. The System Design Tutorial section's URL shortener example is a starting point — practise designing a rate limiter, a chat system, a ride-sharing backend, and a distributed cache before your next interview. The Distributed Systems Roadmap is a 12-month guide — begin today with Martin Kleppmann's book and one hands-on implementation. This Distributed Systems Tutorial 2026 is your reference — revisit each section of the Distributed Systems Tutorial 2026 when the corresponding challenge is live in your work, because Distributed Systems Architecture concepts that seem abstract in study become crystal clear the first time you debug a split-brain scenario or a cascading failure in production. This Distributed Computing Guide is a foundation, not a ceiling — the Distributed Computing Guide you internalise deepest is the one you build your own implementations from. Every concept in this System Design Tutorial has a corresponding implementation waiting — and the System Design Tutorial that sticks is the one you run, break, and fix yourself. Every improvement in Distributed Systems Architecture understanding you make from here compounds into your ability to design systems that are fast, durable, and honest about their failure modes. For Distributed Systems for Beginners, the gap between understanding and fluency is built entirely in the hours spent at a terminal running distributed systems and watching them fail.